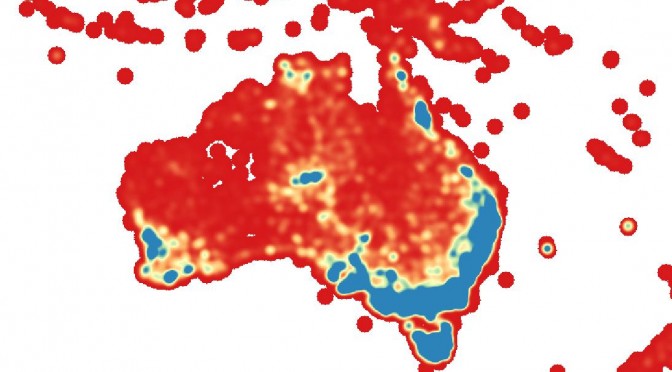
Using data from the Atlas of Living Australia and tools from Mapbox, I created a heatmap of observations of threatened plant species in Australia.
Methods
Preparing the data
I accessed the ALA’s excellent web services API to get the data on threatened plant species observations. I wrote two python scripts to gather this data; the first got the GUIDs (a unique ID) of each plant species that had a Commonwealth conservation status of Rare, Vulnerable, Endangered, or Critically Endangered. Once I had all those GUIDs (around 4000 of them), I ran the second python script which queried the API for all observation records for each GUID (sorry for the server hit, ALA!). Once I had all those observations, I simply stripped the location coordinates out of them, as I didn’t need to know anything more about them for this project, and then wrote the coordinates to a csv file. The result was 11086 coordinates.
Making the map
I loaded up QGIS and imported the csv of coordinates. Following these instructions, I built a heatmap from the coordinate points using a 100 km radius (meaning that the map shows numbers of other records within 100 km) and the Triweight kernel shape. I used a cell size of 0.1 map units (ie, degrees, since I was running this project in WGS84), which I figured would give good enough spatial resolution while keeping file size reasonable for upload. Many of the records I was working with were generalised to 0.1 degrees anyway, in order to protect the exact locations of the conservation-dependent plant species. In order to get the map onto the web, I used Mapbox’s TileMill software. I exported the heatmap from QGIS, reprojecting the image into Google Mercator projection (900913) to make it display properly in TileMill. From TileMill, I uploaded the map into my Mapbox account – and here it is.
Results and Discussion
The Map
Explanation
The legend doesn’t show up in the embedded map, but you can see it in the full map. Here’s an explanation of what the colours actually mean. The numbers displayed in the legend are increments from 0 – 5.69 (roughly). The values refer to the number of records of threatened plant species observations within a 100 km radius of any spot. In the red sections, there were no other records within 100 km (ie there was only one record). In the blue sections, there were at least five other records within 100 km of the cell. The numbers were calculated based on the estimate cumulative cut of the full extent of the map (which may have been the wrong method to use – see below), using a cut value of 2 – 98%.
Discussion
The pattern shown is that the known biodiversity hotspots tend to be blue coloured. This explains the blue in the south west corner, in the area between Melbourne and Adelaide, in Tasmania, and in central Queensland. That’s not a surprise. But this analysis was based on numbers of records, not necessarily numbers of species, and it was based on threatened species only, so there’s some other factors that affect the appearance of the map apart from biodiversity.
The first is survey effort. Areas closest to populated parts of the continent are, by default, likely to be more frequently visited by ecologists, recording observations of species. This explains the heavy blue colour up the east coast, where most of Australia’s population is concentrated. This factor may also explain the high values around Alice Springs in central Australia, Darwin, and Townsville in Queensland, which are not known as biodiversity hotspots, but where research institutions such as herbaria and universities are based, which allow increased recording of data. Survey effort (or lack thereof) may also explain the lack of many records in some areas that are known biodiversity hotspots – for instance, the Kimberley in WA, and to a lesser extent the Pilbara – which does have a faint orange/yellow colour, and which has been relatively highly surveyed due to environmental consultants carrying out environmental impact assessment surveys for the booming mining industry over the past ten years. For that reason, my expectation was that there would be more records in the Pilbara – but there are only a couple of Commonwealth-listed threatened species from the area, which probably explains it. High biodiversity doesn’t necessarily equate to large numbers of threatened species, either for entirely natural reasons, or because of delays in the reporting of data (which are quite likely to be a major contributing factor).
The final factor that may complicate things is that this study looked at threatened species. Therefore, it is likely that there will be more records in areas that have been highly disturbed, such as urban and agricultural areas, because due to Australia’s high rate of endemism, there are many species that only occur within small geographic areas, and when those areas have been heavily modified, it’s likely that those species will have become threatened. Again though, this theory fails to explain the lack of records in the Pilbara, an area that has been heavily disturbed by mining and grazing.
Limitations
Map colours
I wasn’t sure if the method I used to colour the raster image was the most appropriate. The main problem with this method is it fails to discriminate between pixels with higher values. The maximum value present in the raster was 81.977, which is considerably higher than five, which is the value at which the colours stop changing. This means that, although there are relatively few data points at these high levels (the mean value was 1.263, and standard deviation 4.763), the large range is all squished into that one colour. This could potentially hide areas of unusually high threatened species records.
In order to test this, I recoloured the map using the maximum and minimum values rather than the 2-98% cut, and using the actual, rather than estimated values, which takes a little longer (although the difference is negligible for this map), but results in the true (higher) value for the maximum. I also changed the colour increments from continuous (which defaulted to five colour classes) to incremental, and manually specified ten colour classes. The result looked like this:
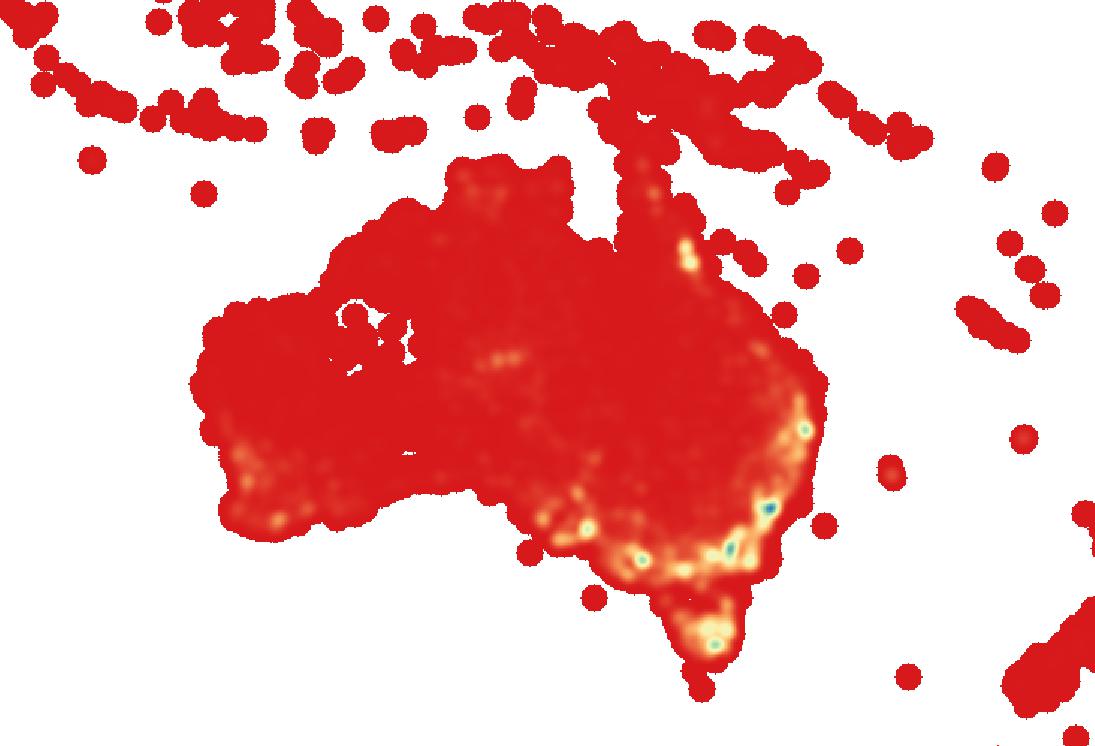
As you can see, this is effective at highlighting the areas of really high observation numbers, however it too has a downside – the vast majority of pixels are now classified at the lowest levels, which means the main body of the variation in the map is invisible.
One solution to this problem is to manually modify the colour breakdown to produce the most visually clear and expressive map. I played around with this, and managed to develop a map which appeared to differentiate between the large number of pixels at the lower end of the spectrum, while allowing those few pixels at the very high end to stand out as highlights. The only downside to this is that it’s a very subjective process. I wanted the map coloration to have a clear mathematical relationship with the data, even if that meant losing a little bit of detail at the top end. For that reason, I stuck with the original method.
Why does Tasmania look so weird?
I don’t know. I think it must be a problem in the process of TileMill creating png map tiles out of the GeoTIFF raster. It’s not present in the raster in QGIS, and it’s not visible at all zoom scales in the TileMill map.
Hi Chid, because of the current ranking parameters I think you’ll find that many of what species which are currently listed threatened aren’t in the places you suggest. Plants that are in botanical hotspots are in the reserve system and are often not considered or listed as rare. Therefore its common to see our most threatened plants are outside of the reserve system. There are of course some mitigating circumstances.
Hi Robert, thanks for your comment. Totally agree that plants in the reserve system may not be listed as threatened although they are in fact conservation dependent, but I’m not convinced this would significantly skew the appearance of the map, because it’s fairly generalised, and there are only a small number of reserves that I can think of (Fitzgerald River Nat Park, maybe some of the Wheatbelt Nature Reserves) that are large enough AND diverse enough to affect a map at this scale. Do you think otherwise? Interested to hear why if so. I’m not quite sure what you mean by “Species which are currently listed threatened aren’t in the places you suggest”. If they’re listed as threatened, then they should appear in the ALA data as such, and I’m simply plotting them out.